With the new Premier League season underway, everyone is anxious to forecast where their favorite team will end up. Although it’s still early, many people are beginning to predict the final table. One of the best ways to do this is by using the soccer pythagorean theorem, as described here.
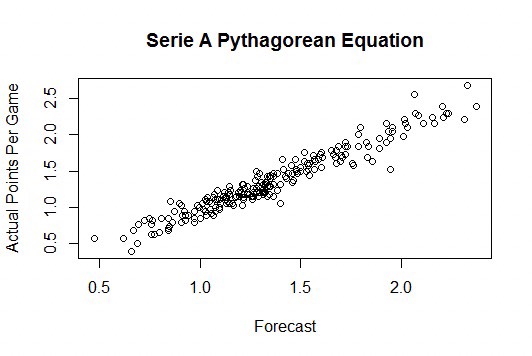
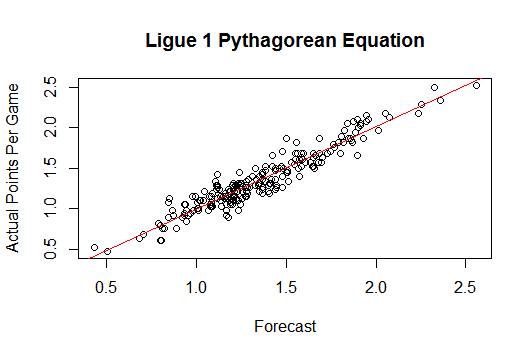
This model essentially uses goals scored and goals conceded to give a team an expected points per game. This can then be used to forecast how a team will fare over the rest of the season. In this article, we are going to go back to the 2017-18 EPL season to analyze the effectiveness of the formula.
In order to do this, we are going to retrospectively perform a mid-season prediction. Basically, we are going to take data from the first 19 games (half the season) of the Premier League, and use that to develop each team’s expected points per game. We will then use the expected points per game value, extrapolate it to the final 19 games of the season, and add that to the initial 19 games, to get a final prediction for the 38 game season.
(If you are curious as to how this whole process works, I suggest reading the previous articles, in which the overall method was outlined)
When this process was performed, I found that, on average, the expected points and final points differed by an average of 4.8 points. That means that this model was able to accurately predict the final standings for each Premier League team with an error of just 0.126 points per game.
In fact, 9 of the teams had expected points and actual points that differed by under 2 points at the end of the season. The model accurately predicted West Ham, Crystal Palace, and Newcastle to climb out of the relegation battle, and also predicted Stoke City’s late struggles.
In this study there were just 6 teams that had a prediction error of 6 points or higher. However, of those teams, 4 of them experienced managerial changes during the season. This would explain the unpredictability of their results, as new staff means new playing styles and new results. When these 3 teams are negated in the study, the average points disparity drops down to just 3.98 points over the course of the entire season.
So, what does this mean for this season? Well, once we get close to a reasonable enough sample size (roughly 10 games, I’d say), we’ll be able to accurately predict the fates of teams in leagues around the world. We’ll be able to judge which teams can stay at the top, which teams will have a late surge, and which teams will be fighting to stay up. It’s an exciting way to track what’s sure to be an exciting season.
Author: Nikhil Mehta